Vorgeschichte
In einer vom CIO der HHU und dem ZIM durchgeführten Evaluation wurden Art und Umfang des Bedarfs der aktuellen und künftigen HPC-Nutzer geklärt. Auf dieser Basis wurde in Konsens mit den Nutzern eine Erweiterungsstrategie entwickelt.
Insbesondere existiert ein stark steigender Bedarf für die Ablage großer Mengen an wissenschaftlichen Daten in einem performanten Cluster-Filesystem. Dies betrifft sowohl die Ablage von sehr großen Dateien (mehrere hundert Gigabyte bis zu einigen Terabyte pro Datei) als auch die Ablage von einigen Millionen zusammengehöriger Einzeldateien.
Benötigt wird daher ein massiver Ausbau des bereits vorhandenen GPFS-basierten Storagesystems im Hinblick auf die Kapazität und die Schaffung von Backup/Redundanz, um die Sicherheit und die Verfügbarkeit der dort abgelegten wissenschaftlichen Daten bestmöglich zu gewährleisten. Angestrebt wurde Ende 2016 eine Nettokapazität von mindestens 1 PByte.
Im November 2017 hat das ZIM dann dem Hersteller des bisherigen GPFS-Systems (DDN, DataDirect Network) der Auftrag zur Erweiterung dieses bestehenden Systems erteilt. Durch gute Verhandlung konnte für die eingeplante Investitionssumme von €1.000.000 eine Kapazität von 2 x 2,8PByte (Nettokapazität, an 2 Standorten) beschafft werden.
Fotostrecke
26.01.2018, 10:13
ENDLICH sind die Komponenten da! Die Teile sind per Flugzeug aus Los Angeles zum Flughafen Düsseldorf gekommen. Dort hat es nochmal drei Tage im Zoll gedauert, aber nun ist alles da. 6 Paletten, zwei davon über 900kg schwer, insgesamt 2400kg Material!

26.01.2018, 10:52
Die neuen Server für NFS und CIFS werden mit 40GigE, als Ethernet mit 40GBit/s, angebunden. Dafür brauchen wir neue Lichtwellenleiter-Kabel. Bei der Gelegenheit räumen wir direkt die ganze LWL-Verkabelung des Clusters auf!

29.01.2018, 14:08
Herr Matthias Wolf von DDN ist gekommen für den Aufbau und Installation. Aber wir bauen lieber alles selber ein - natürlich lassen wir uns vom DDN-Profi instruieren! Hier werden die SAS-Lichtleiterkabel in die Führungsschienen eingebaut.

29.01.2018, 15:56
Die Führungsschienen hängen an den Rackmounts für die Platten-Enclosures. So können diese im Rack, rein- und rausgeschoben werden - im laufenden Betrieb, z.B. um eine defekte Platte zu tauschen.


29.01.2018, 16:32
Insgesamt 1032 Festplatten werden am Ende in diesem System gleichzeitig Ihren Dienst tun. Durch die schiere Anzahl erreichen wir so extrem hohe Geschwindigkeit für Lesen und Schreiben, obwohl wir "nur" normale 8TB SATA-Platten einsetzen.
Jeweils 21 Platten sind in einem Karton. Die müssen jetzt alle in die (noch) leeren Enclosures.



29.01.2018, 17:57
Alle Enclosures sind mit mehreren redundanten optischen SAS-Kabeln mit den RAID-Controllern verbunden. Natürlich haben wir auch hier alle Kabel so verlegt, dass die Enclosures im laufenden Betrieb rein- und rausgeschoben werden können.

Leider hat sich gerade heraus gestellt, dass DDN uns den falschen Controller geliefert hat - das HERZSTÜCK des Systems! Panik und Bestürzung bei DDN-Techniker. Sowas darf bei einem solchen Auftrag einfach nicht passieren. Hektisches Telefonieren und wir sind ziemlich sauer!
Es hilft alles nichts, es muss ein neuer Controller aus den USA eingeflogen werden. Leider wird das dauern! ARGH!!!!!
31.01.2018, 10:59
Wir warten auf den neuen Controller. Aber um nicht untätig zu sein, bauen wir schon mal die neuen "AFM-Nodes" ein. Darüber werden die Daten zischen dem ersten und zweiten Standort synchronisiert und außerdem die Daten über die "Cluster Export Services" als NFS oder CIFS rausgegeben. Beide AFM-Nodes sind mit 2x40GigE ans Uni-Netz angebunden!

31.01.2018, 13:46
Beim Aufbau hat sich schon ziemlich Verpackungsmüll angesammelt! Das können wir natürlich nicht alles in die Tonnen auf dem Campus verteilen. Der Lieferant hat die Pflicht, den Müll abzuholen und fachgerecht zu entsorgen!


02.02.2018, 08:40
Neue Racks sind eingetroffen. Da wird die zweite Instanz drin eingebaut werden. Dadurch soll nicht immer direkt das ganze HPC System lahm liegen, nur weil eine GPFS-Komponente kaputt ist. Es geht dann einfach auf dem zweiten System weiter!

Die Racks sind zu hoch für unsere Türen. Also müssen wir die längst reintragen...
06.02.2018, 09:08
JUHUUU! Der neue Controller ist da!!!

06.02.2018, 09:25
Im Controller sind auch Slots für 2,5'' Platten. Wir bauen hier 2TB-SSDs ein, auf denen die Metadaten gecacht werden!

06.02.2018, 14:11
ES LEBT! Der neue Controller läuft und hat alle 480 Platten erkannt.

21.02.2018, 09:35
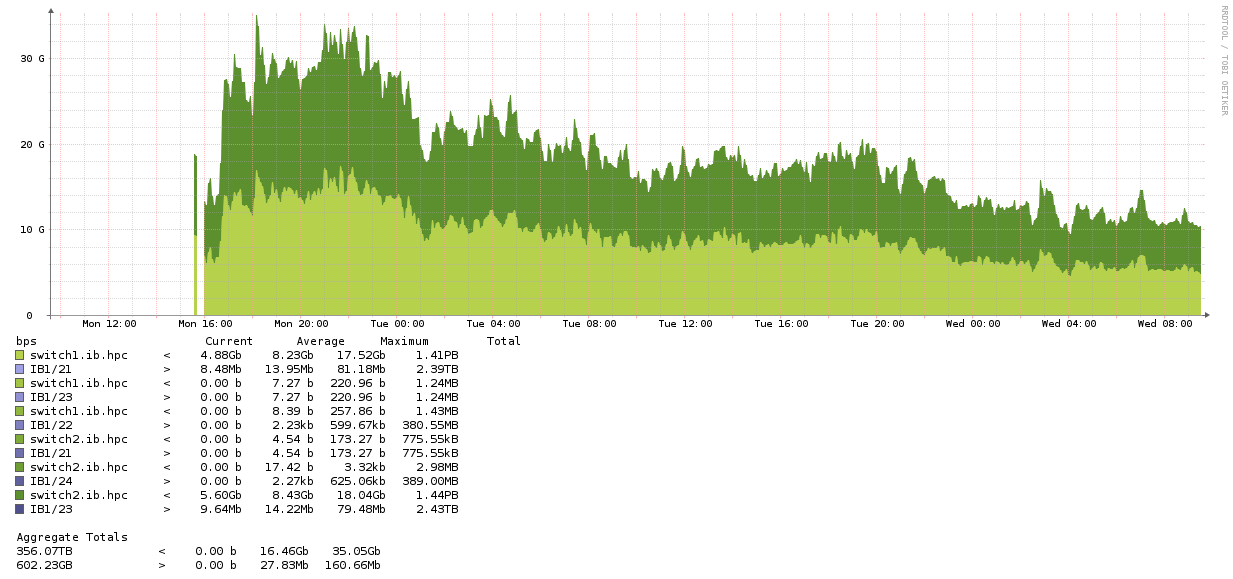
Die Migration der Daten auf dem "alten" GPFS (/scratch_gs) läuft immer noch. Wir haben ein Multithread-fähiges Migrationstool geschrieben um die 495 TByte Daten effizient "rüber" zu kopieren. Die meisten Verzeichnisse sind jetzt schon auf dem neuen System. Nur einige "Monster-Verzeichnisse" von unseren Power-Users brauchen etwas mehr - einige User haben über 100 TByte auf dem System. Das soll ja auch so sein, dafür ist es ja da. Aber es braucht eben beim migrieren etwas - trotz Multithreading.
In der Spitze konnte wir ca. 35 GByte/s erreichen. Das ist schon ziemlich gut!